TOC
由来
Redis以其极高的性能以及支持丰富的数据结构而著称,在互联网行业应用广泛,尤其是KV缓存,以及类似索引的zset有序集合。然而随着服务器CPU核数的增加,Redis单线程的设计也被大家所诟病。因此也萌生了自己实现一个多线程版redis的想法,不过感觉工作量不少,所以一直没有动手
其实在去年就用go实现过一个类似redis的nosql数据库,支持了主要的几种数据结构。不过完成度还不高,还没有主从与集群功能。
前几个星期在知乎看到阿里云的多线程版Redis实现,感觉是个不错的简化方案,而且之前实践过自己的gedis项目,积累了一定的经验,所以就决定自己也薅一个多线程redis出来
有兴趣可以移步github看具体的项目: https://github.com/wosiwo/redis-multithreading
Redis内部实现
工欲善其事必先利其器,动手改造之前先要梳理好redis本身的设计思路
Redis的各个逻辑链
一直觉得接触一个大项目需要抓好切入点(一个是提高效率,一个是容易建立正反馈),虽然代码可读性一直都是大家的追求,不过程序语言到底还是处在人的语言和机器语言中间,通读代码来理出逻辑肯定不是一个高效的办法。
基于之前的实践,感觉从逻辑链入手,是一个比较好的办法,一开始不要把自己困在一个个逻辑实现的细节总,人大脑的并行能力其实很有限,不同层次的逻辑混在一起看,难度就大了很多
//一次Redis请求的执行流程
main(); //入口函数
listenToPort(); //端口监听
aeCreateFileEvent(); //事件触发绑定
aeMain(); //主事件循环
acceptTcpHandler();acceptUnixHandler(); //创建tcp/本地 连接
createClient(); //创建一个新客户端
readQueryFromClient(); //读取客户端的查询缓冲区内容
processInputBuffer(); //处理客户端输入的命令内容
processCommand(); //执行命令
addReply(); //将客户端连接描述符的写事件,绑定到指定的事件循环中
sendReplyToClient(); //reactor线程中将内容输出给客户端
更详细的调用链梳理:CallChain.md
几种多线程模型的对比
了解了Redis本身的逻辑链,下面就可以思考应该应用那种多线程模型
首先是阿里云Redis采用的简化方案,增加多个reactor线程(IO线程)和一个worker线程
这个方案采取了折中的方式,只有一个worker线程负责所有的对数据库的读写操作, 这个就避免了很并行操作数据库的多线程安全问题第二个方案是多个reactor线程,多个worker线程
后面实验性版本,对GET命令做了压测,性能虽然对比第一个方案有一定的提升, 不过对数据库的并行操作如何保障线程安全,又是需要好好考虑的问题了, 而且这样reactor线程+worker线程不能明显超过CPU核心数(或者说线程数),CPU频繁的切换线程, 还是会带来可观的性能损耗的,所以说不如第三个方案第三个方案就是多线程不区分IO线程和工作线程,从IO到命令执行都在同一个线程 (开了实验性的分支,只支持对GET命令的压测)
这个方案的最后的压测效果最好,不过通样也是有并发操作数据库的线程安全问题,对数据库的并行操作, 很显然是没法彻底避免使用锁的,下面会有专门的锻炼来尝试设计一个尽量减少互斥的数据库并行操作的方案第四个方案是综合了第一第三个方案,多个reactor线程,一个worker线程,不过只有写入操作会分配个worker线程,读取命令由reactor线程直接执行
这个方案实现起来会相对简单一些(这个方案还处于TODO状态,不过大体上应该能猜的出, 读取性能指标接近第三个方案,写入的性能接近第一个方案)在开工实现第一个方案的时候还意外发现了唯品会实现的多线程版redis:vire
vire的多线程模型类似于方案3,对数据库的并行操作同个一个比较粗粒度的锁来保证线程安全, (不过vire这个就是一个按照redis思路的一个全新实现了)
多reactor单worker线程模型
目前实现的是第一个方案,这里做一个详细的介绍,先借用阿里云Redis的模型图
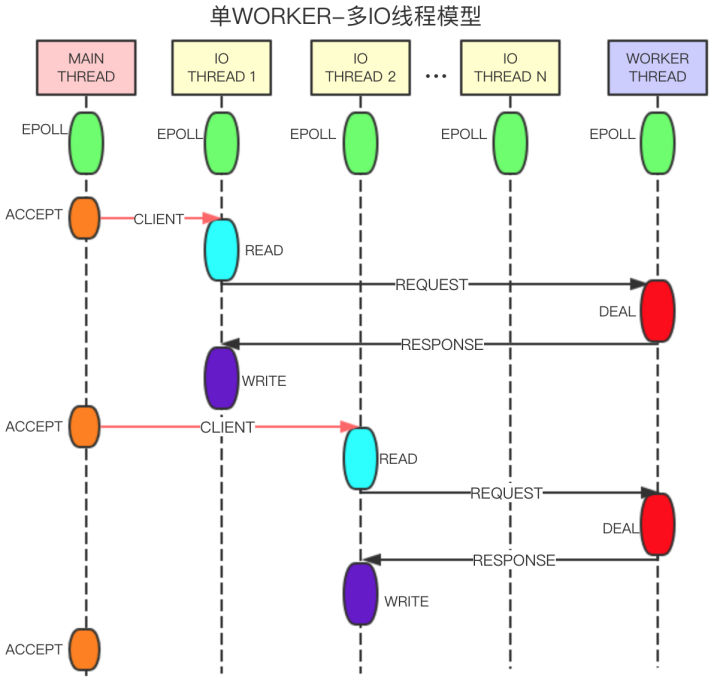
主线程监听端口,当有请求到来时从accepted队列从取出已经就绪的连接描述符,将之加入到某个reactor线程的事件循环中,并指定可读时触发事件,与回调函数
void dispatch2Reactor(int connfd,redisClient *c){ int reactor_id = connfd%server.reactorNum; //连接fd对REACTOR_NUM取余,决定抛给哪个reactor线程 //将connfd加入到指定reactor线程的事件循环中 //reactor线程的事件驱动器被触发后,AE_READABLE类型的事件会被分发到reactorReadHandle函数 aeCreateFileEvent(server.reactors[reactor_id].el,connfd,AE_READABLE,reactorReadHandle, c); }有多个reactor线程,里面都有各自的事件循环,从主线程绑定过来的连接描述符connfd可读时,会执行绑定的回调函数,在回调函数里读取数据,写入到c->querybuf中,并将连接对象添加到线程的无锁队列中,然后使用管道(socketpair)通知worker线程
void reactorReadHandle(aeEventLoop *el,int connfd, void *privdata, int mask){ int ret = readQueryFromClient(el, connfd, privdata, mask); //通过管道通知worker线程 int pipeWriteFd = server.worker[0].pipMasterFd; //将客户端信息添加到当前reactor线程的队列中 atomListAddNodeTail(server.reactors[c->reactor_id].clients,c); //worker线程循环读取队列,可以判断worker线程状态来决定是否通过管道通知worker线程 //避免大量的管道读写带来的开销 if(0==server.worker[0].loopStatus){ ret = write(pipeWriteFd, str, 5); redisLog(REDIS_NOTICE,"reactorReadHandle reactor_id %s write %d connfd %d",str,ret,connfd); } }一个worker线程,也带有事件循环,绑定管道的可读事件,当reactor线程写管道时,会触发可读事件绑定的回调函数,回调函数中,从无锁队列中取出redisclient *c 对象,执行c->querybuf中的请求,将结果写入c->buf,最后将连接connfd再以可写触发类型绑定到reactor线程,由reactor将结果write(connfd)输出给客户端
考虑到管道读写的开销,worker线程会循环的拉取队列内容,直到所有线程的队列都为空,同时worker线程会标记自己的运行状态,尽量避免不必要的管道通信
void workerPipeReadHandle(aeEventLoop *el,int pipfd, void *privdata, int mask){ void *node;int nullNodes = 0; do{ //轮询各个线程的队列,循环弹出所有节点 reactor_id = i%(server.reactorNum); //从无锁队列从取出client信息 redisClient *c = atomListPop(server.reactors[reactor_id].clients); if(NULL==node) nullNodes++; processInputBuffer(c); //执行客户端操作命令 }while(nullNodes<server.reactorNum); //循环取队列 }一开始还用过使用connfd可写事件来触发worker线程,虽然epoll默认是水平触发,可以多次触发可写事件,不过之前测试下来qps好像只有原来的十分之一(还需要更彻底的了解触发机制)
Redis拆分多线程后线程安全问题梳理
先就第一个方案来梳理拆分后遇到的线程安全问题
客户端对象
redisClient *c ,在主线程,reactor线程,woker线程都有可能被操作
- 主线程里面负责创建这个结构体,还有有定时任务会清理所有客户端的c->querybuf空闲空间,以及关闭超时连接
- 缩小客户端查询缓冲区的大小
- 查询缓冲区的大小大于 BIG_ARG 以及 querybuf_peak
- 客户端不活跃,并且缓冲区大于 1k
- 这里定时任务的缩小缓存区的操作有可能触发线程安全问题
- 缩小客户端查询缓冲区的大小
- reactor线程负责从连接描述符connfd中读取请求内容到c->querybuf
- 每个reactor线程有一个无锁队列,在reactor中将 redisClient *c添加到队列中,在worker线程中取出
- worker线程会从c->querybuf读取请求命令并执行
- 最后会由reactor线程将c->buf或c->reply中的内容输出给客户端
- 同一个连接,上一次请求没处理完,下一次请求又到来的话,会操作同一个redisClient *c结构体(主从同步的时候会碰到这种情况)
字典扩容
在数据库字典dict满的时候,会对字典进行扩容,这个时候会有线程安全问题
频道订阅
对channel订阅,与取消订阅的操作,需要改造为无锁队列(pubsubUnsubscribeChannel())
server 全局变量
- 关闭连接时,从server.clients删除连接信息 ln = listSearchKey(server.clients,c);
- 关闭连接时 删除客户端的阻塞信息 ln = listSearchKey(server.unblocked_clients,c);
- 命令执行次数计数server.stat_numcommands
- server.clients 的处理
- 创建客户端对象 c时,添加到链表尾部 listAddNodeTail(server.clients,c);
- 连接关闭时,从链表删除 freeClient(redisClient *c)
- 即使单线程情况下,定时任务也有可能会清理掉执行完,而未输出给客户端的连接信息,—因为单线程下,从读取connfd内容,写入querybuf到命令执行完毕都是连续的,命令执行完后,c->querybuf就可以回收了
- 创建客户端对象 c时,添加到链表尾部 listAddNodeTail(server.clients,c);
事务
TODO 验证多线程对事务是否有影响
集群
多线程下的集群 也是TODO状态
性能优化措施
对线程模型进行优化,以充分利用多核,以及尽可能减少线程间的互斥
无锁队列
先对无锁队列做一个梳理
进队列操作EnQueue(list,x) //进队列改良版 { node = new record(); node->value = x; node->next = NULL; p = list->tail; oldp = p //判断是否空表 if(CAS(&list->tail, NULL, node) == true){ //表尾指针为空 //这里有个需要特别注意的地方,不能直接把node节点赋值给list->head //因为当出队速度快于入队速速,是会把队列取空的,一旦队列取空,是无法原子的同时吧list->head和list->tail原子的置空的 //所以就需要给原队列留下一个种子,保证队列不会完全被置空 //无锁队列的设计很巧妙的通过在初始化队列时,给head指针赋值一个空节点,这个空节点的next指针再指向真正的当前节点 //这样即使在取空队列的时候,仍然会有一个节点被留下来 headNode = new record(); headNode->next = NULL; headNode->prev = NULL; list->head = headNode; if(CAS(&list->head->next, NULL, node)!=true){ //printf("list->head shoud be null except\n"); } }else{ do { while (p->next != NULL) //加这个while循环是因为tail节点是不能保证一定指向最后一个节点的 p = p->next; } while( CAS(&p.next, NULL, node) != TRUE); //如果没有把结点链在尾上,再试 //p.next 表示当前节点已经是事实上的最后一个节点 CAS(&list->tail, oldp, node); //置尾结点 //如果tail指针指向的仍然是循环之前的节点,则将其指向新加入的节点 //tail指针没有变化,说明这中间没有其他线程对链表进行入队操作 //不论是否发生了变化,其实都不能保证tail指针指向的是最后的节点,只是能够在执行这段代码时没有其他线程插入的情况下将tail指针更新到较新的节点 } }出队列操作
DeQueue(list) //出队列 { do{ p = list->head; if (p->next == NULL){ return ERR_EMPTY_QUEUE; } while( CAS(&list->head, p, p->next) != TRUE ); return p->next->value; //返回的是下一个节点的内容 }每个reactor线程维持一个无锁队列,worker线程循环读取各个队列,取空才退出等待下一次通信,大大减少了同个管道进行通信的次数
TODO:线程模型的优化: 也就是前面提到的线程模型方案三,方案四
TODO: 数据库并行操作的方案 :使用原子操作来使得多线程支持SET
TODO:其他复杂数据结构的并行操作(集合,列表,有续集)
压测对比
对各种线程模型的压测对比(后面的两种方案只是实验性质的拉了分支,并没有处理线程安全问题,所以只能对get命令压测)
机器环境
| cpu | 内存 | 操作系统 |
|---|---|---|
| Intel® Xeon® CPU E5-1650 0 @ 3.20GHz (6核12线程) | DDR3 32G | Ubuntu 16.04.4 LTS |
压测结果
| 原版redis3.0 | 多reactor单worker | 多reactor(io线程直接执行命令) | 多reactor多worker(*) | |
|---|---|---|---|---|
| GET | 110533⁄107540 | 304697⁄208500 | 427069.456 | 350202.9 |
| SET | 104119.06 | 217941.196 | ||
| HSET | 101584.73 | 181488.2 | ||
| HGET | 98058.45 | 180018 | ||
| ZADD | 87382.03 | 132996.41 |
//这里直接使用了vire的多线程压测客户端
//e.g get命令的压测 -T 表示压测程序开启的线程数
./tests/vire-benchmark -p 6381 -c 600 -T 12 -t get -n 1000000
GET命令的压测会有两个值,斜杆"/"前是直接对空数据库的GET请求,另一个是有数据情况下的GET请求
从压测对比上看,目前实现的多reactor单worker线程模型(虽然只在空数据集的情况下进行压测),在大部分命令中性能大概是原版redis是两倍,不过还是直接多个工作线程的方案三性能最好
TODO
- 多线程下的集群
- 内存满的时候将淘汰的key落地
- 压测,找出瓶颈,向C10M方向优化
- 加上磁盘搜索功能,让redis不再局限与一个内存数据库(待定)
引用
https://coolshell.cn/articles/8239.html
https://zhuanlan.zhihu.com/p/43422624
comments powered by Disqus